
.jpg)











코드 작업 사용되는 언어모델...코드 요약, 생성, 번역 및 유사성 검사, 취약점 탐지 등 역할
최신 기술이 증가하는 소스코드 취약점 사이버 공격 대응에 널리 활용돼야
[보안뉴스= 박상류 카이스트 사이버보안연구센터 AI 보안팀 연구원] ‘생성형 인공지능(생성형 AI)’의 시대다. 2022년 오픈AI(OpenAI)가 챗GPT를 공개한 이래 마이크로소프트 코파일럿(Copilot), 구글 제미니(Gemini)가, 국내에서는 네이버의 클로바X(CLOVA X), SK텔레콤의 에이닷(A.) 등 다양한 생성형 AI 서비스가 나왔다. 생성형 모델 발전에 따라 프로그램 코드 분야에서는 이를 이용한 코드 생성, 다른 언어로의 번역, 코드 보정 등이 활발히 진행 중이다. 카이스트 사이버보안연구센터(CSRC)는 최근 프로그램 소스코드를 이해하는 언어모델과 함께 이에 기반한 프로그램 소스코드의 취약점 탐지 기술을 분석했다.
언어모델(Language Model)이란 인간의 언어를 이해하고 이를 생성하려는 모델을 말한다. 언어모델은 대용량의 데이터를 학습해 언어 이해를 위한 파라미터를 구축하는 사전학습, 실제 사용자의 목적에 맞는 입·출력 데이터를 학습하는 미세조정 학습으로 나뉜다. 학습을 거친 언어모델 방식은 자연어와 이 형태의 다양한 데이터를 처리하며, 다채로운 작업이 가능하다.
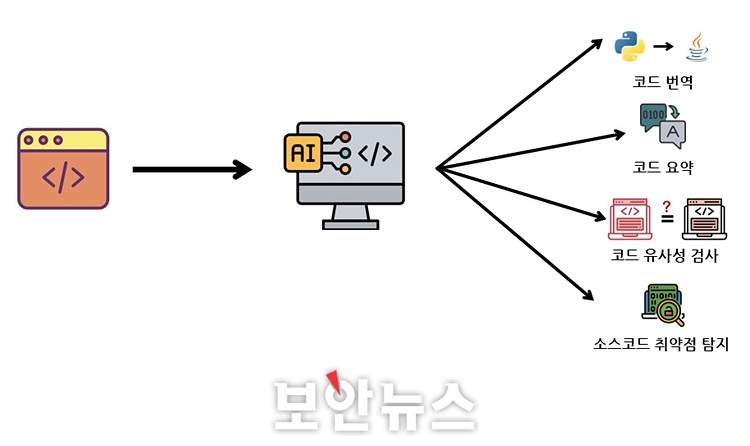
프로그램 코드를 작업하려면 코드와 자연어를 함께 이해하는 언어모델이 필수다. 코드 작업에 사용되는 대표적인 언어모델은 구글의 자연어 처리모델 버트(BERT) 기반 코드버트(CodeBERT), T5 기반 코드T5(CodeT5), 버트 기반 PLBART 등이다. 이들은 △코드 요약 △코드 생성 △코드 번역 △코드 유사성 검사 △소스코드 취약점 탐지 등의 역할을 한다.
먼저 ‘코드 요약’은 입력된 코드에 대한 자연어로 구성된 설명을 생성하는 작업이다. 사용자는 긴 코드를 직접 읽지 않고도 코드 요약을 받을 수 있다. 이어서 ‘코드 생성’은 코드의 자연어 설명에 기반해 프로그램 코드를 생성하는 작업으로 사용자는 설명으로 코드 작성이 가능하다.
‘코드 번역’은 입력받은 코드를 다른 프로그래밍 언어의 코드로 생성이 가능해 재작성이나 같은 프로그램을 다른 언어로의 변환에 활용된다. ‘코드 유사성 검사’는 입력된 두 코드의 유사성을 탐지하는 작업으로, 구조는 다르지만 의미상 비슷한 코드도 탐지 가능하다.
‘소스코드 취약점 탐지’는 취약점 탐지를 통해 기존의 정적·동적 방식이었던 소스코드 취약점 탐지보다 상대적으로 짧은 시간에 취약점을 탐지해 외부 공격을 사전에 방지할 수 있다. 이때 구별형 모델과 생성형 모델을 이용한 소스코드 취약점 탐지의 과정이 다르다.
구별형 언어모델을 활용한 소스코드 취약점 탐지
구별형 언어모델은 입력된 언어를 바탕으로 분류나 회귀 분석에 사용되며 BERT 모델이 대표적이다. 구별형 언어모델을 이용한 소스코드 내 취약점 탐지는 학습 단계와 탐지 단계로 나뉜다. 학습 단계에서는 구별형 언어모델의 미세조정 학습으로 모델이 소스코드 내 취약점을 탐지하도록 구축하고, 탐지 단계에서는 사용자가 입력한 코드의 취약점을 탐지한다.
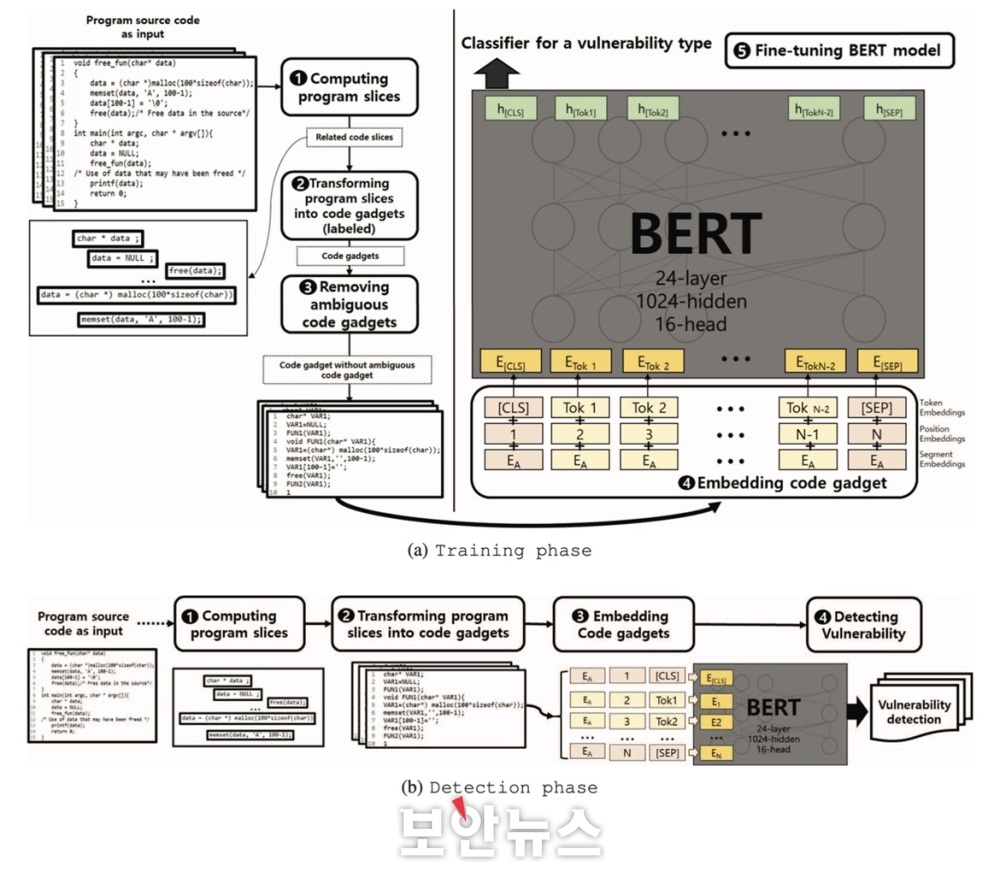
구별형 언어모델을 이용한 소스코드 취약점 탐지 연구 중 하나인 VulDeBERT는 학습 단계에서 코드의 전처리를 수행하고, 이를 BERT에 학습하는 학습 단계와 이후 구축된 모델에 기반해 사용자가 제시한 코드의 취약점을 탐지하는 탐지 단계로 진행된다.
먼저 ‘학습 단계’에서는 소스코드 내 취약점 탐지 모델의 구축을 위해 우선 취약점과 해당 취약점이 내포된 코드 데이터를 수집한다. 이 데이터는 공개된 코드와 취약점을 수집하고, 불필요한 부분 제거, 연관 없는 변수는 단순 토큰으로 대체하는 전처리를 한다. 그 이후 최종 코드 데이터를 구축한다. 구축된 취약점과 코드 데이터는 임베딩(embedding) 과정을 통해 벡터로 변환되는데, 이때 모델이 코드를 쉽게 이해하도록 벡터 시작과 끝에 특정 토큰을 추가한다. 그 다음으로 언어모델의 미세학습 과정을 통해 모델을 구축하며, 별도의 평가데이터로 모델 성능을 평가한다. 또한 추가 전처리와 학습 방법 개선을 통해 최적화된 모델을 구축한다.
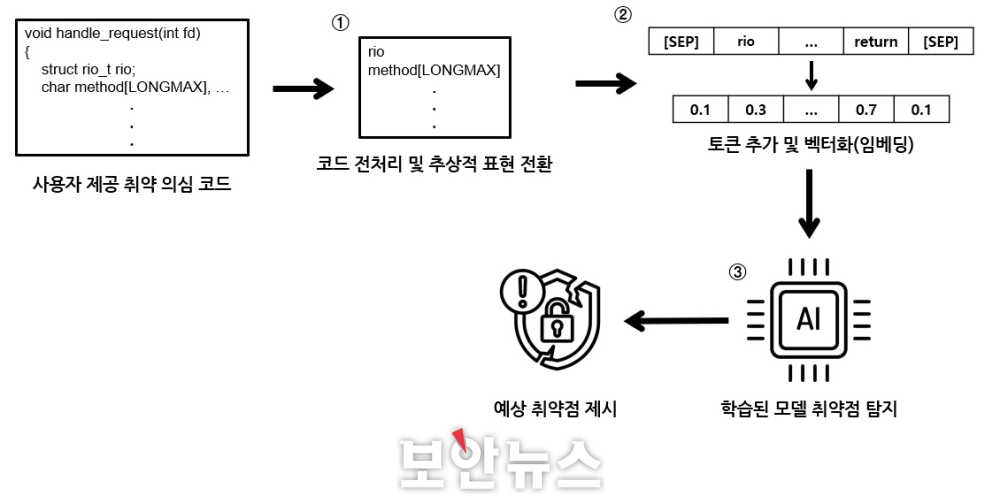
학습 단계에서 구축된 모델은 실제 사용자가 제시한 코드의 취약점 탐지를 수행할 수 있다. ‘탐지 단계’에서는 실제 사용자가 제시한 코드를 입력받아 학습 단계와 같은 전처리 및 임베딩 과정을 거친 후 모델에 탐지 과정을 통해 취약점 유무와 예상되는 취약점을 도출한다.
위 과정을 통한 소스코드 내의 취약점 탐지의 경우, 언어모델이 취약점 탐지에 중요한 코드 구조를 놓칠 수 있어 이를 해결하기 위해 기존 언어모델의 코드를 벡터로 변환 시 코드 내 변수별 관계성을 표현하는 방법이 제안됐다. 모델의 사전학습 및 미세조정 학습을 통해 코드 요소별 연관성을 학습하고 이에 기반한 정확한 취약점 부분을 예상하게 된다.
생성형 언어모델을 활용한 소스코드 취약점 탐지
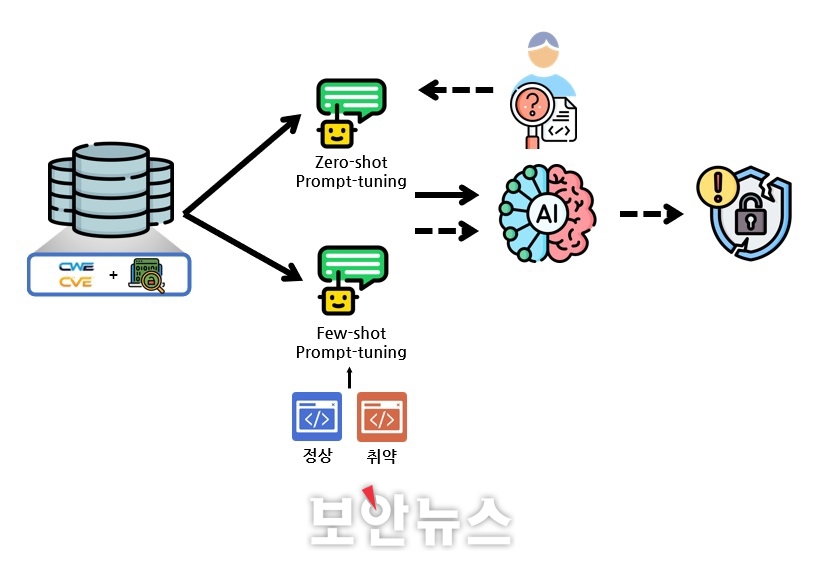
GPT와 같은 생성형 모델은 먼저 나온 단어로 이후 단어를 생성하는 모델이다. 따라서 취약점 탐지에 생성형 언어모델을 적용하기 위해 별도의 미세조정 학습이 진행된다. 생성형 언어모델에서는 전처리를 마친 데이터를 학습 단계 전 추가로 사전에 입력과 모델의 답변 형태를 지정해 모델이 원하는 답변을 유도하는 프롬프트 튜닝(Prompt-tuning)을 진행한다.
구별형 언어모델의 경우 코드를 입력받아 출력값으로 레이블을 제시하도록 설계됐지만, 생성형 언어모델은 입·출력 모두 언어의 형태여야 한다. 따라서 정확한 답변을 얻도록 프롬프트 튜닝을 통해 코드 질의와 취약점 응답 형식의 데이터 쌍을 만드는 과정을 진행한다. 그 이후 학습 단계를 거친 모델은 탐지 단계에서 사용자의 코드에 예상 취약점을 답할 수 있다.
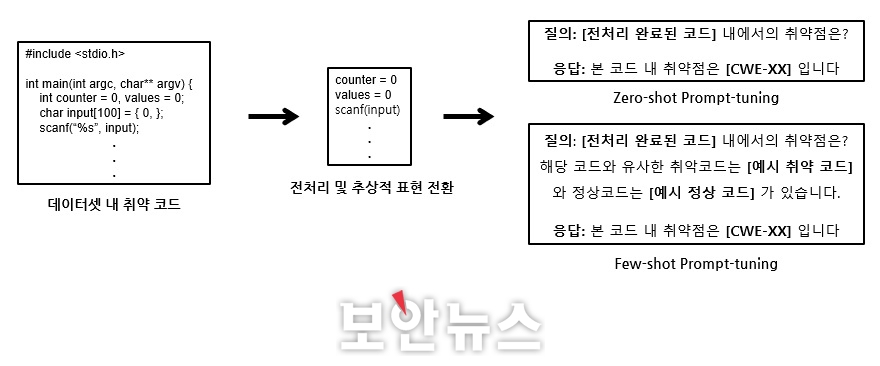
‘프롬프트 튜닝’은 Zero-shot Prompting과 Few-shot Prompting으로 나뉜다. 탐지 대상 코드와 유사한 코드를 모델에 제공하기 위해 유사한 코드를 추출하는 계산 방식에 보정기법을 더해 사용할 수 있다. 하지만 이 방법은 의미상으로 유사한 코드를 제시하지 못한다.
프롬프트 튜닝을 마친 데이터는 구별형 언어모델에서의 소스코드 내 취약점 탐지와 비슷한 ‘학습 단계’를 진행하게 된다. 학습 단계에서는 프롬프트 튜닝을 거친 데이터의 임베딩 과정 후 미세조정 학습을 진행한다. 그리고 모델의 성능 평가를 위해 모델의 답변에서 취약점을 추출하는 후처리 과정으로 성능을 평가한다. 이어 모델 성능에 따라 추가적인 전처리 및 학습 방법 변경 후 재학습 혹은 탐지 모델을 구축한다.
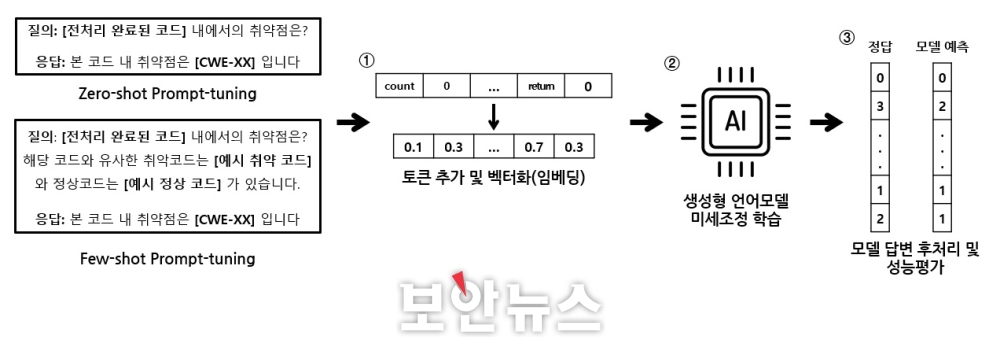
‘탐지 단계’에서도 프롬프트 튜닝과 같은 과정을 거친다. 이후 사용자가 제시한 코드를 질문 형태로 변환한 후, 임베딩 과정을 거쳐 생성형 모델에 질의하고, 생성형 모델은 질의 데이터를 기반으로 프롬프트 튜닝에서 지정했던 답변 형태에 맞게 의심 취약점을 사용자에게 제시한다. 소스코드 취약점 탐지는 프롬프트 튜닝의 과정이 추가된다. 하지만 생성형 모델은 대용량의 사전학습 단계를 진행한 모델이 사용돼 구별형 언어모델보다 유연한 답변을 얻을 수도 있다.
소스코드 취약점 탐지 기술은 소스코드 내의 취약점을 사전에 탐지해 외부 공격을 방지하는 목적으로 연구되고 있다. 언어모델의 발전과 함께 코드를 이해하는 언어모델을 이용한 연구가 활발히 진행되고 있는 것이다. 구별형 언어모델과 생성형 언어모델 등 최신 기술이 지속해서 증가하는 소스코드 취약점 대상 사이버공격에 대응방법으로 널리 활용될 수 있기를 기대한다.
[글_박상류 카이스트 사이버보안연구센터 AI 보안팀 연구원]
최신 기술이 증가하는 소스코드 취약점 사이버 공격 대응에 널리 활용돼야
[보안뉴스= 박상류 카이스트 사이버보안연구센터 AI 보안팀 연구원] ‘생성형 인공지능(생성형 AI)’의 시대다. 2022년 오픈AI(OpenAI)가 챗GPT를 공개한 이래 마이크로소프트 코파일럿(Copilot), 구글 제미니(Gemini)가, 국내에서는 네이버의 클로바X(CLOVA X), SK텔레콤의 에이닷(A.) 등 다양한 생성형 AI 서비스가 나왔다. 생성형 모델 발전에 따라 프로그램 코드 분야에서는 이를 이용한 코드 생성, 다른 언어로의 번역, 코드 보정 등이 활발히 진행 중이다. 카이스트 사이버보안연구센터(CSRC)는 최근 프로그램 소스코드를 이해하는 언어모델과 함께 이에 기반한 프로그램 소스코드의 취약점 탐지 기술을 분석했다.
▲코드를 이해하는 언어모델을 활용한 주요 작업[자료=카이스트 CSRC]
언어모델(Language Model)이란 인간의 언어를 이해하고 이를 생성하려는 모델을 말한다. 언어모델은 대용량의 데이터를 학습해 언어 이해를 위한 파라미터를 구축하는 사전학습, 실제 사용자의 목적에 맞는 입·출력 데이터를 학습하는 미세조정 학습으로 나뉜다. 학습을 거친 언어모델 방식은 자연어와 이 형태의 다양한 데이터를 처리하며, 다채로운 작업이 가능하다.
프로그램 코드를 작업하려면 코드와 자연어를 함께 이해하는 언어모델이 필수다. 코드 작업에 사용되는 대표적인 언어모델은 구글의 자연어 처리모델 버트(BERT) 기반 코드버트(CodeBERT), T5 기반 코드T5(CodeT5), 버트 기반 PLBART 등이다. 이들은 △코드 요약 △코드 생성 △코드 번역 △코드 유사성 검사 △소스코드 취약점 탐지 등의 역할을 한다.
먼저 ‘코드 요약’은 입력된 코드에 대한 자연어로 구성된 설명을 생성하는 작업이다. 사용자는 긴 코드를 직접 읽지 않고도 코드 요약을 받을 수 있다. 이어서 ‘코드 생성’은 코드의 자연어 설명에 기반해 프로그램 코드를 생성하는 작업으로 사용자는 설명으로 코드 작성이 가능하다.
‘코드 번역’은 입력받은 코드를 다른 프로그래밍 언어의 코드로 생성이 가능해 재작성이나 같은 프로그램을 다른 언어로의 변환에 활용된다. ‘코드 유사성 검사’는 입력된 두 코드의 유사성을 탐지하는 작업으로, 구조는 다르지만 의미상 비슷한 코드도 탐지 가능하다.
‘소스코드 취약점 탐지’는 취약점 탐지를 통해 기존의 정적·동적 방식이었던 소스코드 취약점 탐지보다 상대적으로 짧은 시간에 취약점을 탐지해 외부 공격을 사전에 방지할 수 있다. 이때 구별형 모델과 생성형 모델을 이용한 소스코드 취약점 탐지의 과정이 다르다.
구별형 언어모델을 활용한 소스코드 취약점 탐지
구별형 언어모델은 입력된 언어를 바탕으로 분류나 회귀 분석에 사용되며 BERT 모델이 대표적이다. 구별형 언어모델을 이용한 소스코드 내 취약점 탐지는 학습 단계와 탐지 단계로 나뉜다. 학습 단계에서는 구별형 언어모델의 미세조정 학습으로 모델이 소스코드 내 취약점을 탐지하도록 구축하고, 탐지 단계에서는 사용자가 입력한 코드의 취약점을 탐지한다.
▲VulDeBERT 학습 및 탐지 과정 개요[자료=카이스트 CSRC]
구별형 언어모델을 이용한 소스코드 취약점 탐지 연구 중 하나인 VulDeBERT는 학습 단계에서 코드의 전처리를 수행하고, 이를 BERT에 학습하는 학습 단계와 이후 구축된 모델에 기반해 사용자가 제시한 코드의 취약점을 탐지하는 탐지 단계로 진행된다.
먼저 ‘학습 단계’에서는 소스코드 내 취약점 탐지 모델의 구축을 위해 우선 취약점과 해당 취약점이 내포된 코드 데이터를 수집한다. 이 데이터는 공개된 코드와 취약점을 수집하고, 불필요한 부분 제거, 연관 없는 변수는 단순 토큰으로 대체하는 전처리를 한다. 그 이후 최종 코드 데이터를 구축한다. 구축된 취약점과 코드 데이터는 임베딩(embedding) 과정을 통해 벡터로 변환되는데, 이때 모델이 코드를 쉽게 이해하도록 벡터 시작과 끝에 특정 토큰을 추가한다. 그 다음으로 언어모델의 미세학습 과정을 통해 모델을 구축하며, 별도의 평가데이터로 모델 성능을 평가한다. 또한 추가 전처리와 학습 방법 개선을 통해 최적화된 모델을 구축한다.
▲구별형 언어모델 취약점 탐지 단계 과정[자료=카이스트 CSRC]
학습 단계에서 구축된 모델은 실제 사용자가 제시한 코드의 취약점 탐지를 수행할 수 있다. ‘탐지 단계’에서는 실제 사용자가 제시한 코드를 입력받아 학습 단계와 같은 전처리 및 임베딩 과정을 거친 후 모델에 탐지 과정을 통해 취약점 유무와 예상되는 취약점을 도출한다.
위 과정을 통한 소스코드 내의 취약점 탐지의 경우, 언어모델이 취약점 탐지에 중요한 코드 구조를 놓칠 수 있어 이를 해결하기 위해 기존 언어모델의 코드를 벡터로 변환 시 코드 내 변수별 관계성을 표현하는 방법이 제안됐다. 모델의 사전학습 및 미세조정 학습을 통해 코드 요소별 연관성을 학습하고 이에 기반한 정확한 취약점 부분을 예상하게 된다.
▲생성형 언어모델 기반의 소스코드 취약점 탐지 기술 개요[자료=카이스트 CSRC]
생성형 언어모델을 활용한 소스코드 취약점 탐지
GPT와 같은 생성형 모델은 먼저 나온 단어로 이후 단어를 생성하는 모델이다. 따라서 취약점 탐지에 생성형 언어모델을 적용하기 위해 별도의 미세조정 학습이 진행된다. 생성형 언어모델에서는 전처리를 마친 데이터를 학습 단계 전 추가로 사전에 입력과 모델의 답변 형태를 지정해 모델이 원하는 답변을 유도하는 프롬프트 튜닝(Prompt-tuning)을 진행한다.
구별형 언어모델의 경우 코드를 입력받아 출력값으로 레이블을 제시하도록 설계됐지만, 생성형 언어모델은 입·출력 모두 언어의 형태여야 한다. 따라서 정확한 답변을 얻도록 프롬프트 튜닝을 통해 코드 질의와 취약점 응답 형식의 데이터 쌍을 만드는 과정을 진행한다. 그 이후 학습 단계를 거친 모델은 탐지 단계에서 사용자의 코드에 예상 취약점을 답할 수 있다.
▲생성형 언어모델 기반 취약점 탐지 프롬프트 튜닝 과정[자료=카이스트 CSRC]
‘프롬프트 튜닝’은 Zero-shot Prompting과 Few-shot Prompting으로 나뉜다. 탐지 대상 코드와 유사한 코드를 모델에 제공하기 위해 유사한 코드를 추출하는 계산 방식에 보정기법을 더해 사용할 수 있다. 하지만 이 방법은 의미상으로 유사한 코드를 제시하지 못한다.
프롬프트 튜닝을 마친 데이터는 구별형 언어모델에서의 소스코드 내 취약점 탐지와 비슷한 ‘학습 단계’를 진행하게 된다. 학습 단계에서는 프롬프트 튜닝을 거친 데이터의 임베딩 과정 후 미세조정 학습을 진행한다. 그리고 모델의 성능 평가를 위해 모델의 답변에서 취약점을 추출하는 후처리 과정으로 성능을 평가한다. 이어 모델 성능에 따라 추가적인 전처리 및 학습 방법 변경 후 재학습 혹은 탐지 모델을 구축한다.
▲생성형 언어모델 기반 취약점 탐지 학습 단계[자료=카이스트 CSRC]
‘탐지 단계’에서도 프롬프트 튜닝과 같은 과정을 거친다. 이후 사용자가 제시한 코드를 질문 형태로 변환한 후, 임베딩 과정을 거쳐 생성형 모델에 질의하고, 생성형 모델은 질의 데이터를 기반으로 프롬프트 튜닝에서 지정했던 답변 형태에 맞게 의심 취약점을 사용자에게 제시한다. 소스코드 취약점 탐지는 프롬프트 튜닝의 과정이 추가된다. 하지만 생성형 모델은 대용량의 사전학습 단계를 진행한 모델이 사용돼 구별형 언어모델보다 유연한 답변을 얻을 수도 있다.
소스코드 취약점 탐지 기술은 소스코드 내의 취약점을 사전에 탐지해 외부 공격을 방지하는 목적으로 연구되고 있다. 언어모델의 발전과 함께 코드를 이해하는 언어모델을 이용한 연구가 활발히 진행되고 있는 것이다. 구별형 언어모델과 생성형 언어모델 등 최신 기술이 지속해서 증가하는 소스코드 취약점 대상 사이버공격에 대응방법으로 널리 활용될 수 있기를 기대한다.
[글_박상류 카이스트 사이버보안연구센터 AI 보안팀 연구원]
<저작권자: 보안뉴스(www.boannews.com) 무단전재-재배포금지>
 김영명기자 기사보기
김영명기자 기사보기







































.png)



.jpg)



