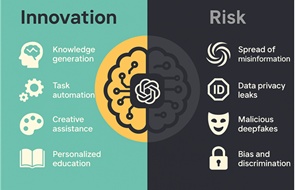
.jpg)











6Пљ 18РЯКЮХЭ ЧбБЙОю РНМК, ЧяНКФЩОю, РкРВСжЧр Ею 170СО, AI ЧуКъ ХыЧи АГЙц
AIЁЄЕЅРЬХЭ БтОї, ДыЧа, КДПј Ею 674АГ БтОїЁЄБтАќАњ 4ИИПЉ Иэ БЙЙЮ ТќПЉ
ЧѕНХ УЂУтЁЄШЎЛъРЛ РЬВј ЁЎРЮАјСіДЩ ЕЅРЬХЭ ШАПыЧљРЧШИЁЏЕЕ УтЙќ
[КИОШДКНК РЬЛѓПь БтРк] АњЧаБтМњСЄКИХыНХКЮ(РхАќ РгЧ§Мї, РЬЧЯ АњБтСЄХыКЮ)ПЭ ЧбБЙСіДЩСЄКИЛчШИСјШяПј(ПјРх ЙЎПыНФ, РЬЧЯ СіДЩСЄКИПј)РЬ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭ 170СО(4Оя 8,000ИИ АЧ)РЛ РЮАјСіДЩЧуКъ ШЈЦфРЬСіИІ ХыЧи 6Пљ 18РЯКЮХЭ АГЙцЧбДй. ЖЧЧб, АњБтСЄХыКЮДТ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭРЧ ШАПы УЫСјАњ МКАњ ШЎЛъ ЕюРЛ РЇЧи 6Пљ 18РЯ ПРРќ 10НУ, LGЛчРЬО№НКЦФХЉПЁМ ЁЎРЮАјСіДЩ(AI) ЕЅРЬХЭ ШАПыЧљРЧШИЁЏ УтЙќНФРЛ АЎАэ, РЧАпМіЗХРЛ РЇЧб АЃДуШИИІ АГУжЧпДй.

АњБтСЄХыКЮДТ 2017ГтКЮХЭ БтОї, ПЌБИРк, АГРЮ ЕюРЬ НУАЃ Йз КёПы ЙЎСІЗЮ АГКА БИУрЧЯБт ОюЗСПю РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭИІ БИУрЁЄАГЙцЧпРИИч, 2020ГтКЮХЭДТ Е№СіХа ДКЕє ЁЎЕЅРЬХЭ ДяЁЏ БИУр ЧСЗЮСЇЦЎРЧ РЯШЏРИЗЮ БИУр БдИ№ИІ ДыЦј ШЎДыЧи УпСј СпРЬДй.
БзЕПОШ 21СОРЧ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭИІ БИУрЁЄАГЙцЧи AI ЧуКъ РЬПыРкПЭ ЕЅРЬХЭ ШАПыРЬ КќИЃАд СѕАЁЧЯАэ РжРИИч, АГЙц ЕЅРЬХЭИІ ШАПыЧб РЮАјСіДЩ МКёНК АГЙп Йз МКДЩ ЧтЛѓ ЕюРЧ МКАњЕЕ ГЊХИГЊАэ РжДй.
АГЙц ЕЅРЬХЭ 170СО СжПф ЦЏТЁ
РЬЙјПЁ АГЙцЧЯДТ 8Ды КаОп 170СОРЧ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭДТ ЕЅРЬХЭ БтШЙКЮХЭ БИУрБюСі ЛъОїАш, РќЙЎАЁЛгИИ ОЦДЯЖѓ, ИЙРК БЙЙЮЕщРЬ ТќПЉЧб АсАњЙАРЬДй.
ПьМБ, ЙЮАЃРЧ БЄЙќРЇЧб МіПфИІ ЙйХСРИЗЮ КаОпКА ЛъЁЄЧаЁЄПЌ РќЙЎАЁ, СжПф ШАПыБтОї ЕюРЬ СїСЂ ТќПЉЧи ЧбБЙОю РНМК ЕЅРЬХЭ, БЙГЛ ЕЕЗЮСжЧр ПЕЛѓ ЕЅРЬХЭ, СжПф ОЯСњШЏ ПЕЛѓ ЕЅРЬХЭ Ею ЦФБоШПАњАЁ ХЉАэ ЙЮАЃПЁМ ДыБдИ№ЗЮ БИУрЧЯБт ОюЗСПю РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭИІ БтШЙЧпДй.
ЕЅРЬХЭ БИУрПЁДТ БЙГЛ СжПф РЮАјСіДЩЁЄЕЅРЬХЭ РќЙЎБтОїРК ЙАЗа СжПф ДыЧа(МПяДы, KAIST Ею 48АГ), КДПј(МПяДыКДПј, ОЦЛъКДПј Ею 25АГ) Ею Уб 674АГ БтОїЁЄБтАќРЬ ДыАХ ТќПЉЧпРИИч, ЦЏШї, ЕЅРЬХЭ МіС§ЁЄАЁАј Ею БИУр АњСЄПЁ АцЗТДмР§ПЉМК, УыОїСиКёУЛГт Ею БЙЙЮ ДЉБИГЊ ТќПЉЧв Мі РжДТ ХЉЖѓПьЕхМвНЬ ЙцНФРЛ ЕЕРдЧи 4ИИПЉ ИэРЬЖѓДТ ИЙРК БЙЙЮЕщРЧ ТќПЉИІ РЬВјОюГТДй.
AI ЧуКъПЁ ДыБдИ№ЗЮ АГЙцЕЧДТ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭРЧ ЧАСњАњ ШАПыМКРЛ АЫСѕЧЯАэ АќИЎЧЯДТ АњСЄПЁЕЕ КаОпКА РќЙЎАЁПЭ РќЙЎБтАќ, ШАПыБтОї ЕюРЬ ШћРЛ И№ОвДй. СіГЧи 9ПљКЮХЭ 8Ды КаОпКА ЛъЁЄЧаЁЄПЌ РќЙЎАЁ 80ПЉИэРЬ ТќПЉЧЯДТ ЁЎЧАСњРкЙЎРЇЁЏИІ ПюПЕЧи РќЙЎРћ ЧАСњАќИЎ СіПјУМАшИІ БИУрЧпАэ, СжПф ДыБтОї(ГзРЬЙі, LG, ЛяМКРќРк, KT, ЧіДыТї Ею), НКХИЦЎОї(ЕіГыРЬЕх, НКЦЎЖѓЕхКёСЏ, КёЙйПЃПЁНК Ею), ДыЧа Йз ПЌБИБтАќ(KAIST, GIST, ETRI, ГѓСЄПј Ею) Ею 20ПЉАГ БтОїЁЄБтАќРЬ ТќПЉЧи ЕЅРЬХЭ АГЙц Рќ, ШАПыМК АЫХфИІ СјЧр(5~6Пљ)Чи НЧСІ МіПфРкАЁ ПфБИЧЯДТ ЕЅРЬХЭ ЧАСњРЛ ШЎКИЧЯАэРк ЧпДй.
АњБтСЄХыКЮПЭ СіДЩСЄКИПјРК ЕЅРЬХЭ АГЙц ШФПЁЕЕ РЬПыРк ТќПЉЧќ С§СпАГМББтАЃ ПюПЕ(~9Пљ) ЕюРЛ ХыЧи РЬПыРкРЧ ПфБИЛчЧзРЛ РћБи ЙнПЕЧЯДТ Ею ЙЮЁЄАќ ЧљЗТРЛ БтЙнРИЗЮ ЕЅРЬХЭИІ СіМгРћРИЗЮ АГМБЧиГЊАЅ АшШЙРЬДй.
РЬЙјПЁ РЮАјСіДЩ(AI) ЧуКъПЁ АГЙцЕЧДТ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭДТ КёПыАњ РЮЗТ ШЎКИ ЕюРЧ ЙЎСІЗЮ ЕЅРЬХЭИІ СїСЂ БИУрЧЯБт ОюЗСПю СпМвБтОїРЬГЊ НКХИЦЎОїЛг ОЦДЯЖѓ, ДыБтОїЕЕ РкУМ ШЎКИЧЯБт ОюЗСПю ДыБдИ№ ЕЅРЬХЭИІ СІАјЧбДйДТ СЁПЁМ БзЕПОШ БЙГЛ РЮАјСіДЩ ЛъОїАшПЁМ АЁРх ХЋ АЩИВЕЙЗЮ ВХРК ЙЎСІРЮ ЁЎЕЅРЬХЭ АЅСѕЁЏРЛ ОюДР СЄЕЕ ЧиМвЧв Мі РжРЛ АЭРИЗЮ РќИСЕШДй.
БзАЃ БЙГЛ РЮАјСіДЩ БтОїЕщРК РЮАјСіДЩ АГЙпПЁ ЧЪПфЧб ЕЅРЬХЭ ШЎКИИІ РЇЧи ЧиПм ПРЧТЕЅРЬХЭИІ ИЙРЬ ШАПыЧиПдДй. БзЗЏГЊ ЧбБЙОю, БЙГЛ ЕЕЗЮШЏАц Ею БЙГЛ НЧСЄРЛ ЙнПЕЧЯСі ИјЧб ПРЧТЕЅРЬХЭДТ БЙГЛ РЮАјСіДЩ МКёНК АГЙпПЁ ШАПыЕЧБт ОюЗСПю ЙЎСІАЁ РжОњДй. РЬЙјПЁДТ СіПЊКА ЙцО№РЛ ЦїЧдЧб ЧбБЙОю, БЙГЛ СжПф ЕЕЗЮПЭ БЙГЛ ШЏРк РЧЗсПЕЛѓ ЕЅРЬХЭ Ею ЁЎЧбБЙЧќ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭЁЏАЁ ДыЦј ШЎУцЕХ, БЙЙЮРЬ УМАЈЧв Мі РжДТ РЮАјСіДЩ(AI) МКёНК АГЙпРЬ АЁМгШЕЩ Мі РжРЛ АЭРИЗЮ БтДыЕШДй.
ДыЧЅРћРИЗЮ, ПРДТ 6Пљ 30РЯ АјАГИІ ОеЕЮАэ РжДТ ЧбБЙОю ЙцО№(АцЛѓЁЄРќЖѓЁЄУцУЛЁЄАПјЁЄСІСж) ЙпШ ЕЅРЬХЭДТ ЧЅСиОюПЁ КёЧи ЛчХѕИЎИІ Рп РЮНФЧЯСі ИјЧЯДј РНМК БтЙн РЮАјСіДЩ(AI) МКёНКРЧ ЙЎСІСЁРЛ ЛѓДч КЮКа ЧиАсЧв Мі РжРЛ АЭРИЗЮ КИРЮДй. ЦЏШї, ЕЅРЬХЭ АГЙц Рќ ШАПыМК АЫХф АсАњ ЁЎРкПЌНКЗЏПю ЙцО№РЬ МіС§ЕЪЁЏ, ЁЎБтСИ МКёНКРЧ РЮНФЗќРЬ 12% ЧтЛѓЕЪЁЏ ЕюРЧ ССРК ЦђАЁИІ ЙоБтЕЕ ЧпДй.
ЖЧЧб, 6Пљ 18РЯКЮХЭ 6Пљ 30РЯБюСі МјТїРћРИЗЮ АјАГЕЩ РкРВСжЧр ЕЅРЬХЭ(21СО)ДТ БЙГЛ ЕЕЗЮСжЧр ПЕЛѓЛг ОЦДЯЖѓ, СжТї РхОжЙАЁЄРЬЕПУМ РЮСі ПЕЛѓ, ЙіНК ГыМБСжЧр ПЕЛѓ Ею ДйУЄЗЮПю ЕЅРЬХЭИІ СІАјЧи РкРВСжЧрТї АГЙпРЛ ЧбУў ОеДчБц АЭРИЗЮ БтДыЕЧАэ РжДй. ЦЏШї, ШАПыМК АЫХф АсАњ, ЁЎЦЏМі ТїМБ, РхОжЙА, ЦїЦЎШІ Ею ДйОчЧб АДУМАЁ ЦїЧдЁЏЕШ СЁРК ДыЧЅРћРЮ РхСЁРИЗЮ ВХШљДй.
БзЕПОШ АњБтСЄХыКЮПЭ СіДЩСЄКИПјРК ЧАСњАќИЎ РќЙЎБтАќРЮ ЧбБЙСЄКИХыНХБтМњЧљШИ(TTA) Йз РќЙЎБтОї ЕюАњ ЧљЗТЧи АэЧАСњРЧ ЕЅРЬХЭИІ ОШРќЧЯАд ШАПыЧЯЕЕЗЯ ЕЅРЬХЭ ЧАСњАќИЎ МіСиРЛ ДыЦј АШЧи ПдРИИч, ЧтШФ АГРЮСЄКИРЇПЭ АГРЮСЄКИ РќЙЎБтАќРЮ ЧбБЙРЮХЭГнСјШяПј(KISA) ЕюАњЕЕ СіМгРћРИЗЮ ЧљЗТРЛ АШЧи ГЊАЅ АшШЙРЬДй.
TTAДТ РќЙЎАЁ Йз ШАПыБтОї РЧАп МіЗХРЛ ХыЧи ЧАСњБтСиРЛ СЄИГЧЯАэ, РЬИІ РћПыЧи РќЙнРћРЮ ЕЅРЬХЭ ЧАСњРЛ АЫСѕЧпДй. СіДЩСЄКИПјРК РЮАјСіДЩ ЕЅРЬХЭИІ ОШНЩЧЯАэ ЛчПыЧв Мі РжДТ ШАПы ПЉАЧРЛ СЖМКЧЯБт РЇЧи РЬЙЬСіПЭ ПЕЛѓ ЕЅРЬХЭРЧ АцПь ЛчРќПЁ АГРЮСЄКИ ЕПРЧИІ ЙоОЦ БИУрЧЯДТ ЧбЦэ, АГРЮСЄКИ ЕюРЬ ЦїЧдЕЧСі ОЪЕЕЗЯ ЧбБЙОю ХиНКЦЎ ЕЅРЬХЭ ЕюРК НУГЊИЎПРИІ БтЙнРИЗЮ УЂРлЧб РчЧі ЕЅРЬХЭЗЮ БИУрЧпДй.
РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭ ШАПы ШАМКШ ЙцОШ
АњБтСЄХыКЮДТ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭРЧ ДыБдИ№ АГЙцАњ ЧдВВ ЕЅРЬХЭ ШАПы УЫСјАњ МКАњ ШЎЛъ ЕюРЛ РЇЧи 6Пљ 18РЯ ЁЎРЮАјСіДЩ(AI) ЕЅРЬХЭ ШАПыЧљРЧШИЁЏ УтЙќНФРЛ АЎАэ, ЧіРх АЃДуШИИІ АГУжЧи ЕЅРЬХЭИІ НЧСІЗЮ ШАПыЧЯДТ БтОїЁЄБтАќЕщРЧ Л§Л§Чб РЧАпРЛ МіЗХЧпДй.
ЁЎРЮАјСіДЩ(AI) ЕЅРЬХЭ ШАПыЧљРЧШИЁЏДТ ЕЅРЬХЭ ЧАСњАќИЎ РќЙЎБтАќРЮ TTAПЭ РЬЙј 170СО ЕЅРЬХЭРЧ ШАПыМК АЫХфПЁ ТќПЉЧб БтОїЁЄБтАќРЛ СпНЩРИЗЮ БИМКЕЦРИИч, РЮАјСіДЩ(AI) ЧуКъ ЕЅРЬХЭИІ РћБи ШАПыЧЯАэ МКАњИІ АјРЏЁЄШЎЛъЧЯДТ ЧбЦэ, ЕЅРЬХЭ ЧАСњ СІАэПЭ СіМгРћ АГМБПЁ ЧљЗТЧи ГЊАЅ ПЙСЄРЬДй. СіДЩСЄКИПј(NIA)РК ЧтШФ ТќПЉИІ ШёИСЧЯДТ БтОї Йз БтАќРЛ СпНЩРИЗЮ ЧљРЧШИИІ СіМгРћРИЗЮ ШЎДыЧи ГЊАЅ АшШЙРЬДй.
РЬПЭ ЧдВВ СіДЩСЄКИПјРК ДыБдИ№ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭРЧ КЛАнРћРЮ АГЙцПЁ ЙпИТУч AI ЧуКъ ШАПыШЏАцРЛ ДыЦј АГМБЧбДй. КЛРЮРЮСѕ Чб ЙјИИРИЗЮ ЕЅРЬХЭПЁ ДыЧб СЂБй Йз ШАПыРЬ АЁДЩЧЯЕЕЗЯ ШИПјАЁРд НУНКХлРЛ АГМБЧЯАэ, СїАќРћРЮ ЕЅРЬХЭ ХНЛіРЛ РЇЧи UIПЭ UXЕЕ АГМБЧпДй. ПУ ЧЯЙнБтПЁДТ ЕЅРЬХЭ АЫЛіУМАшИІ АњСІИэ СпНЩПЁМ РкЕПТї, ЧЅСіЦЧ Ею ЛчЙАЁЄАДУМ СпНЩРИЗЮ АГЦэЧв АшШЙРЬДй. ЖЧЧб, РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭИІ ШАПыЧб ОЫАэИЎСђ АэЕЕШ ЕюРЛ СіПјЧЯБт РЇЧи ЕЅРЬХЭ ШАПы АцСјДыШИЕЕ УпСјЧЯИч, ЧяНКФЩОю ЕЅРЬХЭРЧ ШАПы ШАМКШИІ РЇЧи ЦѓМтЧќ ОШНЩСИРЧ ШЎДы Йз ХЌЖѓПьЕх БтЙнРЧ АГЙцЧќ ОШНЩСИ БИУрЕЕ УпСјЧбДй.
ЕЅРЬХЭ АГЙцРЯСЄ Йз ШФМгСЖФЁ АшШЙРК?
АњБтСЄХыКЮПЭ СіДЩСЄКИПјРК 2020ГтПЁ БИУрЧб 8Ды КаОп 170СОРЧ ЕЅРЬХЭИІ 6Пљ 18РЯ 60СОРЛ НУРлРИЗЮ 6ПљИЛБюСі МјТїРћРИЗЮ АГЙцЧв ПЙСЄРЬДй. ЦЏШї, ЧяНКФЩОю ЕЅРЬХЭ(27СО) Ею АГРЮСЄКИ Йз ЙЮАЈСЄКИАЁ ЦїЧдЕЩ ПьЗСАЁ РжДТ 59СОРЧ ЕЅРЬХЭДТ УжСОАЫСѕРЛ АХУФ 6Пљ 30РЯПЁ АГЙцЧв АшШЙРЬДй.
РЬЙј АГЙцРК ЕЅРЬХЭ СІАјАњ ДѕКвОю, РЬПыРкПЭ ЧдВВ Дѕ ГЊРК ЕЅРЬХЭ СІАјРЛ РЇЧб АГМБСЁРЛ УЃБт РЇЧи 9ПљИЛБюСі 3АГПљАЃРЧ ТќПЉЧќ ЕЅРЬХЭ С§Сп АГМББтАЃРЛ ПюПЕЧбДй. ЕЅРЬХЭ АГЙцАњ ЧдВВ, РЮАјСіДЩ(AI) ЧуКъПЁ ЕЅРЬХЭ АГМБРЧАп МіЗХРЛ РЇЧб ПТЖѓРЮ УЂБИИІ ПюПЕЧЯАэ, РќЙЎБтАќ(TTA, KISA Ею)Ањ ЧљЗТЧи ЕЅРЬХЭ ЧАСњ Ею РЬПыРк РЧАпПЁ НХМгЧЯАд ДыРРЧЯБт РЇЧб TFИІ ПюПЕЧбДй. ЧиДч БтАЃ ЕПОШ ЕЅРЬХЭ АГМБПЁ ЕЕПђРЬ ЕЧДТ РЧАпРЛ СІНУЧб РЬПыРкПЁАдДТ УпУЗРЛ ХыЧи МвСЄРЧ ЛѓЧАЕЕ СіБоЧи ТќПЉИІ ЕЖЗСЧв ПЙСЄРЬДй.
АњБтСЄХыКЮ РгЧ§Мї РхАќРК ЁАДяРЧ ЙАРЬ ДыСі АїАїРИЗЮ НКИчЕщОю ВЩРЛ ЧЧПьЕэРЬ, РЬЙјПЁ АјАГЕЧДТ ЕЅРЬХЭЕщРЬ ЛъОї АїАїПЁМ ГЮИЎШАПыЕХ ЧѕНХРЧ ПИХИІ ИЮРЛ Мі РжБтИІ БтДыЧбДйЁБИч, ЁАСЄКЮЕЕ АэЧАСњРЧ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭИІ СіМгРћРИЗЮ СІАјЧЯАэ, ДЉБИГЊ ЕЅРЬХЭИІ НБАд ШАПыЧЯАэ МКАњИІ АјРЏЧв Мі РжДТ ШЏАцРЛ СЖМКЧЯДТ ЕЅ СіПјРЛ ОЦГЂСі ОЪАкДйЁБАэ АСЖЧпДй.
[РЬЛѓПь БтРк(boan@boannews.com)]
AIЁЄЕЅРЬХЭ БтОї, ДыЧа, КДПј Ею 674АГ БтОїЁЄБтАќАњ 4ИИПЉ Иэ БЙЙЮ ТќПЉ
ЧѕНХ УЂУтЁЄШЎЛъРЛ РЬВј ЁЎРЮАјСіДЩ ЕЅРЬХЭ ШАПыЧљРЧШИЁЏЕЕ УтЙќ
[КИОШДКНК РЬЛѓПь БтРк] АњЧаБтМњСЄКИХыНХКЮ(РхАќ РгЧ§Мї, РЬЧЯ АњБтСЄХыКЮ)ПЭ ЧбБЙСіДЩСЄКИЛчШИСјШяПј(ПјРх ЙЎПыНФ, РЬЧЯ СіДЩСЄКИПј)РЬ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭ 170СО(4Оя 8,000ИИ АЧ)РЛ РЮАјСіДЩЧуКъ ШЈЦфРЬСіИІ ХыЧи 6Пљ 18РЯКЮХЭ АГЙцЧбДй. ЖЧЧб, АњБтСЄХыКЮДТ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭРЧ ШАПы УЫСјАњ МКАњ ШЎЛъ ЕюРЛ РЇЧи 6Пљ 18РЯ ПРРќ 10НУ, LGЛчРЬО№НКЦФХЉПЁМ ЁЎРЮАјСіДЩ(AI) ЕЅРЬХЭ ШАПыЧљРЧШИЁЏ УтЙќНФРЛ АЎАэ, РЧАпМіЗХРЛ РЇЧб АЃДуШИИІ АГУжЧпДй.
ЁуАњБтСЄХыКЮАЁ АГЙцЧЯДТ ЧаНРПы ЕЅРЬХЭ 170СО[РкЗс=АњЧаБтМњСЄКИХыНХКЮ]
АњБтСЄХыКЮДТ 2017ГтКЮХЭ БтОї, ПЌБИРк, АГРЮ ЕюРЬ НУАЃ Йз КёПы ЙЎСІЗЮ АГКА БИУрЧЯБт ОюЗСПю РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭИІ БИУрЁЄАГЙцЧпРИИч, 2020ГтКЮХЭДТ Е№СіХа ДКЕє ЁЎЕЅРЬХЭ ДяЁЏ БИУр ЧСЗЮСЇЦЎРЧ РЯШЏРИЗЮ БИУр БдИ№ИІ ДыЦј ШЎДыЧи УпСј СпРЬДй.
БзЕПОШ 21СОРЧ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭИІ БИУрЁЄАГЙцЧи AI ЧуКъ РЬПыРкПЭ ЕЅРЬХЭ ШАПыРЬ КќИЃАд СѕАЁЧЯАэ РжРИИч, АГЙц ЕЅРЬХЭИІ ШАПыЧб РЮАјСіДЩ МКёНК АГЙп Йз МКДЩ ЧтЛѓ ЕюРЧ МКАњЕЕ ГЊХИГЊАэ РжДй.
АГЙц ЕЅРЬХЭ 170СО СжПф ЦЏТЁ
РЬЙјПЁ АГЙцЧЯДТ 8Ды КаОп 170СОРЧ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭДТ ЕЅРЬХЭ БтШЙКЮХЭ БИУрБюСі ЛъОїАш, РќЙЎАЁЛгИИ ОЦДЯЖѓ, ИЙРК БЙЙЮЕщРЬ ТќПЉЧб АсАњЙАРЬДй.
ПьМБ, ЙЮАЃРЧ БЄЙќРЇЧб МіПфИІ ЙйХСРИЗЮ КаОпКА ЛъЁЄЧаЁЄПЌ РќЙЎАЁ, СжПф ШАПыБтОї ЕюРЬ СїСЂ ТќПЉЧи ЧбБЙОю РНМК ЕЅРЬХЭ, БЙГЛ ЕЕЗЮСжЧр ПЕЛѓ ЕЅРЬХЭ, СжПф ОЯСњШЏ ПЕЛѓ ЕЅРЬХЭ Ею ЦФБоШПАњАЁ ХЉАэ ЙЮАЃПЁМ ДыБдИ№ЗЮ БИУрЧЯБт ОюЗСПю РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭИІ БтШЙЧпДй.
ЕЅРЬХЭ БИУрПЁДТ БЙГЛ СжПф РЮАјСіДЩЁЄЕЅРЬХЭ РќЙЎБтОїРК ЙАЗа СжПф ДыЧа(МПяДы, KAIST Ею 48АГ), КДПј(МПяДыКДПј, ОЦЛъКДПј Ею 25АГ) Ею Уб 674АГ БтОїЁЄБтАќРЬ ДыАХ ТќПЉЧпРИИч, ЦЏШї, ЕЅРЬХЭ МіС§ЁЄАЁАј Ею БИУр АњСЄПЁ АцЗТДмР§ПЉМК, УыОїСиКёУЛГт Ею БЙЙЮ ДЉБИГЊ ТќПЉЧв Мі РжДТ ХЉЖѓПьЕхМвНЬ ЙцНФРЛ ЕЕРдЧи 4ИИПЉ ИэРЬЖѓДТ ИЙРК БЙЙЮЕщРЧ ТќПЉИІ РЬВјОюГТДй.
AI ЧуКъПЁ ДыБдИ№ЗЮ АГЙцЕЧДТ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭРЧ ЧАСњАњ ШАПыМКРЛ АЫСѕЧЯАэ АќИЎЧЯДТ АњСЄПЁЕЕ КаОпКА РќЙЎАЁПЭ РќЙЎБтАќ, ШАПыБтОї ЕюРЬ ШћРЛ И№ОвДй. СіГЧи 9ПљКЮХЭ 8Ды КаОпКА ЛъЁЄЧаЁЄПЌ РќЙЎАЁ 80ПЉИэРЬ ТќПЉЧЯДТ ЁЎЧАСњРкЙЎРЇЁЏИІ ПюПЕЧи РќЙЎРћ ЧАСњАќИЎ СіПјУМАшИІ БИУрЧпАэ, СжПф ДыБтОї(ГзРЬЙі, LG, ЛяМКРќРк, KT, ЧіДыТї Ею), НКХИЦЎОї(ЕіГыРЬЕх, НКЦЎЖѓЕхКёСЏ, КёЙйПЃПЁНК Ею), ДыЧа Йз ПЌБИБтАќ(KAIST, GIST, ETRI, ГѓСЄПј Ею) Ею 20ПЉАГ БтОїЁЄБтАќРЬ ТќПЉЧи ЕЅРЬХЭ АГЙц Рќ, ШАПыМК АЫХфИІ СјЧр(5~6Пљ)Чи НЧСІ МіПфРкАЁ ПфБИЧЯДТ ЕЅРЬХЭ ЧАСњРЛ ШЎКИЧЯАэРк ЧпДй.
АњБтСЄХыКЮПЭ СіДЩСЄКИПјРК ЕЅРЬХЭ АГЙц ШФПЁЕЕ РЬПыРк ТќПЉЧќ С§СпАГМББтАЃ ПюПЕ(~9Пљ) ЕюРЛ ХыЧи РЬПыРкРЧ ПфБИЛчЧзРЛ РћБи ЙнПЕЧЯДТ Ею ЙЮЁЄАќ ЧљЗТРЛ БтЙнРИЗЮ ЕЅРЬХЭИІ СіМгРћРИЗЮ АГМБЧиГЊАЅ АшШЙРЬДй.
РЬЙјПЁ РЮАјСіДЩ(AI) ЧуКъПЁ АГЙцЕЧДТ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭДТ КёПыАњ РЮЗТ ШЎКИ ЕюРЧ ЙЎСІЗЮ ЕЅРЬХЭИІ СїСЂ БИУрЧЯБт ОюЗСПю СпМвБтОїРЬГЊ НКХИЦЎОїЛг ОЦДЯЖѓ, ДыБтОїЕЕ РкУМ ШЎКИЧЯБт ОюЗСПю ДыБдИ№ ЕЅРЬХЭИІ СІАјЧбДйДТ СЁПЁМ БзЕПОШ БЙГЛ РЮАјСіДЩ ЛъОїАшПЁМ АЁРх ХЋ АЩИВЕЙЗЮ ВХРК ЙЎСІРЮ ЁЎЕЅРЬХЭ АЅСѕЁЏРЛ ОюДР СЄЕЕ ЧиМвЧв Мі РжРЛ АЭРИЗЮ РќИСЕШДй.
БзАЃ БЙГЛ РЮАјСіДЩ БтОїЕщРК РЮАјСіДЩ АГЙпПЁ ЧЪПфЧб ЕЅРЬХЭ ШЎКИИІ РЇЧи ЧиПм ПРЧТЕЅРЬХЭИІ ИЙРЬ ШАПыЧиПдДй. БзЗЏГЊ ЧбБЙОю, БЙГЛ ЕЕЗЮШЏАц Ею БЙГЛ НЧСЄРЛ ЙнПЕЧЯСі ИјЧб ПРЧТЕЅРЬХЭДТ БЙГЛ РЮАјСіДЩ МКёНК АГЙпПЁ ШАПыЕЧБт ОюЗСПю ЙЎСІАЁ РжОњДй. РЬЙјПЁДТ СіПЊКА ЙцО№РЛ ЦїЧдЧб ЧбБЙОю, БЙГЛ СжПф ЕЕЗЮПЭ БЙГЛ ШЏРк РЧЗсПЕЛѓ ЕЅРЬХЭ Ею ЁЎЧбБЙЧќ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭЁЏАЁ ДыЦј ШЎУцЕХ, БЙЙЮРЬ УМАЈЧв Мі РжДТ РЮАјСіДЩ(AI) МКёНК АГЙпРЬ АЁМгШЕЩ Мі РжРЛ АЭРИЗЮ БтДыЕШДй.
ДыЧЅРћРИЗЮ, ПРДТ 6Пљ 30РЯ АјАГИІ ОеЕЮАэ РжДТ ЧбБЙОю ЙцО№(АцЛѓЁЄРќЖѓЁЄУцУЛЁЄАПјЁЄСІСж) ЙпШ ЕЅРЬХЭДТ ЧЅСиОюПЁ КёЧи ЛчХѕИЎИІ Рп РЮНФЧЯСі ИјЧЯДј РНМК БтЙн РЮАјСіДЩ(AI) МКёНКРЧ ЙЎСІСЁРЛ ЛѓДч КЮКа ЧиАсЧв Мі РжРЛ АЭРИЗЮ КИРЮДй. ЦЏШї, ЕЅРЬХЭ АГЙц Рќ ШАПыМК АЫХф АсАњ ЁЎРкПЌНКЗЏПю ЙцО№РЬ МіС§ЕЪЁЏ, ЁЎБтСИ МКёНКРЧ РЮНФЗќРЬ 12% ЧтЛѓЕЪЁЏ ЕюРЧ ССРК ЦђАЁИІ ЙоБтЕЕ ЧпДй.
ЖЧЧб, 6Пљ 18РЯКЮХЭ 6Пљ 30РЯБюСі МјТїРћРИЗЮ АјАГЕЩ РкРВСжЧр ЕЅРЬХЭ(21СО)ДТ БЙГЛ ЕЕЗЮСжЧр ПЕЛѓЛг ОЦДЯЖѓ, СжТї РхОжЙАЁЄРЬЕПУМ РЮСі ПЕЛѓ, ЙіНК ГыМБСжЧр ПЕЛѓ Ею ДйУЄЗЮПю ЕЅРЬХЭИІ СІАјЧи РкРВСжЧрТї АГЙпРЛ ЧбУў ОеДчБц АЭРИЗЮ БтДыЕЧАэ РжДй. ЦЏШї, ШАПыМК АЫХф АсАњ, ЁЎЦЏМі ТїМБ, РхОжЙА, ЦїЦЎШІ Ею ДйОчЧб АДУМАЁ ЦїЧдЁЏЕШ СЁРК ДыЧЅРћРЮ РхСЁРИЗЮ ВХШљДй.
БзЕПОШ АњБтСЄХыКЮПЭ СіДЩСЄКИПјРК ЧАСњАќИЎ РќЙЎБтАќРЮ ЧбБЙСЄКИХыНХБтМњЧљШИ(TTA) Йз РќЙЎБтОї ЕюАњ ЧљЗТЧи АэЧАСњРЧ ЕЅРЬХЭИІ ОШРќЧЯАд ШАПыЧЯЕЕЗЯ ЕЅРЬХЭ ЧАСњАќИЎ МіСиРЛ ДыЦј АШЧи ПдРИИч, ЧтШФ АГРЮСЄКИРЇПЭ АГРЮСЄКИ РќЙЎБтАќРЮ ЧбБЙРЮХЭГнСјШяПј(KISA) ЕюАњЕЕ СіМгРћРИЗЮ ЧљЗТРЛ АШЧи ГЊАЅ АшШЙРЬДй.
TTAДТ РќЙЎАЁ Йз ШАПыБтОї РЧАп МіЗХРЛ ХыЧи ЧАСњБтСиРЛ СЄИГЧЯАэ, РЬИІ РћПыЧи РќЙнРћРЮ ЕЅРЬХЭ ЧАСњРЛ АЫСѕЧпДй. СіДЩСЄКИПјРК РЮАјСіДЩ ЕЅРЬХЭИІ ОШНЩЧЯАэ ЛчПыЧв Мі РжДТ ШАПы ПЉАЧРЛ СЖМКЧЯБт РЇЧи РЬЙЬСіПЭ ПЕЛѓ ЕЅРЬХЭРЧ АцПь ЛчРќПЁ АГРЮСЄКИ ЕПРЧИІ ЙоОЦ БИУрЧЯДТ ЧбЦэ, АГРЮСЄКИ ЕюРЬ ЦїЧдЕЧСі ОЪЕЕЗЯ ЧбБЙОю ХиНКЦЎ ЕЅРЬХЭ ЕюРК НУГЊИЎПРИІ БтЙнРИЗЮ УЂРлЧб РчЧі ЕЅРЬХЭЗЮ БИУрЧпДй.
РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭ ШАПы ШАМКШ ЙцОШ
АњБтСЄХыКЮДТ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭРЧ ДыБдИ№ АГЙцАњ ЧдВВ ЕЅРЬХЭ ШАПы УЫСјАњ МКАњ ШЎЛъ ЕюРЛ РЇЧи 6Пљ 18РЯ ЁЎРЮАјСіДЩ(AI) ЕЅРЬХЭ ШАПыЧљРЧШИЁЏ УтЙќНФРЛ АЎАэ, ЧіРх АЃДуШИИІ АГУжЧи ЕЅРЬХЭИІ НЧСІЗЮ ШАПыЧЯДТ БтОїЁЄБтАќЕщРЧ Л§Л§Чб РЧАпРЛ МіЗХЧпДй.
ЁЎРЮАјСіДЩ(AI) ЕЅРЬХЭ ШАПыЧљРЧШИЁЏДТ ЕЅРЬХЭ ЧАСњАќИЎ РќЙЎБтАќРЮ TTAПЭ РЬЙј 170СО ЕЅРЬХЭРЧ ШАПыМК АЫХфПЁ ТќПЉЧб БтОїЁЄБтАќРЛ СпНЩРИЗЮ БИМКЕЦРИИч, РЮАјСіДЩ(AI) ЧуКъ ЕЅРЬХЭИІ РћБи ШАПыЧЯАэ МКАњИІ АјРЏЁЄШЎЛъЧЯДТ ЧбЦэ, ЕЅРЬХЭ ЧАСњ СІАэПЭ СіМгРћ АГМБПЁ ЧљЗТЧи ГЊАЅ ПЙСЄРЬДй. СіДЩСЄКИПј(NIA)РК ЧтШФ ТќПЉИІ ШёИСЧЯДТ БтОї Йз БтАќРЛ СпНЩРИЗЮ ЧљРЧШИИІ СіМгРћРИЗЮ ШЎДыЧи ГЊАЅ АшШЙРЬДй.
РЬПЭ ЧдВВ СіДЩСЄКИПјРК ДыБдИ№ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭРЧ КЛАнРћРЮ АГЙцПЁ ЙпИТУч AI ЧуКъ ШАПыШЏАцРЛ ДыЦј АГМБЧбДй. КЛРЮРЮСѕ Чб ЙјИИРИЗЮ ЕЅРЬХЭПЁ ДыЧб СЂБй Йз ШАПыРЬ АЁДЩЧЯЕЕЗЯ ШИПјАЁРд НУНКХлРЛ АГМБЧЯАэ, СїАќРћРЮ ЕЅРЬХЭ ХНЛіРЛ РЇЧи UIПЭ UXЕЕ АГМБЧпДй. ПУ ЧЯЙнБтПЁДТ ЕЅРЬХЭ АЫЛіУМАшИІ АњСІИэ СпНЩПЁМ РкЕПТї, ЧЅСіЦЧ Ею ЛчЙАЁЄАДУМ СпНЩРИЗЮ АГЦэЧв АшШЙРЬДй. ЖЧЧб, РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭИІ ШАПыЧб ОЫАэИЎСђ АэЕЕШ ЕюРЛ СіПјЧЯБт РЇЧи ЕЅРЬХЭ ШАПы АцСјДыШИЕЕ УпСјЧЯИч, ЧяНКФЩОю ЕЅРЬХЭРЧ ШАПы ШАМКШИІ РЇЧи ЦѓМтЧќ ОШНЩСИРЧ ШЎДы Йз ХЌЖѓПьЕх БтЙнРЧ АГЙцЧќ ОШНЩСИ БИУрЕЕ УпСјЧбДй.
ЕЅРЬХЭ АГЙцРЯСЄ Йз ШФМгСЖФЁ АшШЙРК?
АњБтСЄХыКЮПЭ СіДЩСЄКИПјРК 2020ГтПЁ БИУрЧб 8Ды КаОп 170СОРЧ ЕЅРЬХЭИІ 6Пљ 18РЯ 60СОРЛ НУРлРИЗЮ 6ПљИЛБюСі МјТїРћРИЗЮ АГЙцЧв ПЙСЄРЬДй. ЦЏШї, ЧяНКФЩОю ЕЅРЬХЭ(27СО) Ею АГРЮСЄКИ Йз ЙЮАЈСЄКИАЁ ЦїЧдЕЩ ПьЗСАЁ РжДТ 59СОРЧ ЕЅРЬХЭДТ УжСОАЫСѕРЛ АХУФ 6Пљ 30РЯПЁ АГЙцЧв АшШЙРЬДй.
РЬЙј АГЙцРК ЕЅРЬХЭ СІАјАњ ДѕКвОю, РЬПыРкПЭ ЧдВВ Дѕ ГЊРК ЕЅРЬХЭ СІАјРЛ РЇЧб АГМБСЁРЛ УЃБт РЇЧи 9ПљИЛБюСі 3АГПљАЃРЧ ТќПЉЧќ ЕЅРЬХЭ С§Сп АГМББтАЃРЛ ПюПЕЧбДй. ЕЅРЬХЭ АГЙцАњ ЧдВВ, РЮАјСіДЩ(AI) ЧуКъПЁ ЕЅРЬХЭ АГМБРЧАп МіЗХРЛ РЇЧб ПТЖѓРЮ УЂБИИІ ПюПЕЧЯАэ, РќЙЎБтАќ(TTA, KISA Ею)Ањ ЧљЗТЧи ЕЅРЬХЭ ЧАСњ Ею РЬПыРк РЧАпПЁ НХМгЧЯАд ДыРРЧЯБт РЇЧб TFИІ ПюПЕЧбДй. ЧиДч БтАЃ ЕПОШ ЕЅРЬХЭ АГМБПЁ ЕЕПђРЬ ЕЧДТ РЧАпРЛ СІНУЧб РЬПыРкПЁАдДТ УпУЗРЛ ХыЧи МвСЄРЧ ЛѓЧАЕЕ СіБоЧи ТќПЉИІ ЕЖЗСЧв ПЙСЄРЬДй.
АњБтСЄХыКЮ РгЧ§Мї РхАќРК ЁАДяРЧ ЙАРЬ ДыСі АїАїРИЗЮ НКИчЕщОю ВЩРЛ ЧЧПьЕэРЬ, РЬЙјПЁ АјАГЕЧДТ ЕЅРЬХЭЕщРЬ ЛъОї АїАїПЁМ ГЮИЎШАПыЕХ ЧѕНХРЧ ПИХИІ ИЮРЛ Мі РжБтИІ БтДыЧбДйЁБИч, ЁАСЄКЮЕЕ АэЧАСњРЧ РЮАјСіДЩ ЧаНРПы ЕЅРЬХЭИІ СіМгРћРИЗЮ СІАјЧЯАэ, ДЉБИГЊ ЕЅРЬХЭИІ НБАд ШАПыЧЯАэ МКАњИІ АјРЏЧв Мі РжДТ ШЏАцРЛ СЖМКЧЯДТ ЕЅ СіПјРЛ ОЦГЂСі ОЪАкДйЁБАэ АСЖЧпДй.
[РЬЛѓПь БтРк(boan@boannews.com)]
<РњРлБЧРк: КИОШДКНК(www.boannews.com) ЙЋДмРќРч-РчЙшЦїБнСі>
 РЬЛѓПьБтРк БтЛчКИБт
РЬЛѓПьБтРк БтЛчКИБт
































 [2025-04-07]
[2025-04-07] 





.jpg)








